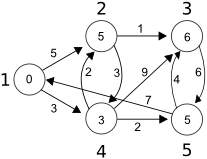
In this article I describe a way of modifying Dijkstra’s Alogrithm in order to find all the shortest path from a source to a node.
This article assumes you know how Dijkstra’s Algorithm works. If you don’t, see my previous post or the Wikipedia article.
The Problem
You know how to use Dijkstra’s algorithm to find the length of the shortest path to a node. You’ve even figured out how to record the path to each node. But you what you really need are all the shortest paths leading to a node.
The Idea
I can help, but to be honest, this is obvious.
In order to record the path to each node, I used an array to record which node comes before each other node in the shortest path. That is to say: prev[i] was the node that comes just before node i in the shortest path from the source to node i.
To record all the shortest paths that lead to a node, I just turned prev into a matrix with the following meaning: prev[i][0] is the number of nodes that could come before node i on a path of minimum length; prev[i][1..] are the nodes that could come before node i on path of minimum length.
#include <stdio.h>
#define GRAPHSIZE 2048
#define INFINITY GRAPHSIZE*GRAPHSIZE
#define MAX(a, b) ((a > b) ? (a) : (b))
int e; /* The number of nonzero edges in the graph */
int n; /* The number of nodes in the graph */
long dist[GRAPHSIZE][GRAPHSIZE]; /* dist[i][j] is the distance between node i and j; or 0 if there is no direct connection */
long d[GRAPHSIZE]; /* d[i] is the length of the shortest path between the source (s) and node i */
int prev[GRAPHSIZE][GRAPHSIZE + 1]; /* prev[i] holds the nodes that could comes right before i in the shortest path from the source to i;
prev[i][0] is the number of nodes and prev[i][1..] are the nodes */
void printD() {
int i;
printf("Distances:\n");
for (i = 1; i <= n; ++i)
printf("%10d", i);
printf("\n");
for (i = 1; i <= n; ++i) {
printf("%10ld", d[i]);
}
printf("\n");
}
/*
* Prints the shortest path from the source to dest.
*
* dijkstra(int) MUST be run at least once BEFORE
* this is called
*/
void printPath(int dest, int depth) {
int i, j;
printf("-%d\n", dest);
for (i = 1; i <= prev[dest][0]; ++i) {
for (j = 0; j <= depth; ++j)
printf(" |");
printPath(prev[dest][i], depth + 1);
}
}
void dijkstra(int s) {
int i, k, mini;
int visited[GRAPHSIZE];
for (i = 1; i <= n; ++i) {
d[i] = INFINITY;
prev[i][0] = 0; /* no path has yet been found to i */
visited[i] = 0; /* the i-th element has not yet been visited */
}
d[s] = 0;
for (k = 1; k <= n; ++k) {
mini = -1;
for (i = 1; i <= n; ++i)
if (!visited[i] && ((mini == -1) || (d[i] < d[mini])))
mini = i;
visited[mini] = 1;
for (i = 1; i <= n; ++i)
if (dist[mini][i]) {
if (d[mini] + dist[mini][i] < d[i]) { /* a shorter path has been found */
d[i] = d[mini] + dist[mini][i];
prev[i][0] = 1;
prev[i][1] = mini;
} else if (d[mini] + dist[mini][i] == d[i]) { /* a path of the same length has been found */
++prev[i][0];
prev[i][prev[i][0]] = mini;
}
}
}
}
int main(int argc, char *argv[]) {
int i, j;
int u, v, w;
FILE *fin = fopen("dist.txt", "r");
fscanf(fin, "%d", &e);
for (i = 0; i < e; ++i)
for (j = 0; j < e; ++j)
dist[i][j] = 0;
n = -1;
for (i = 0; i < e; ++i) {
fscanf(fin, "%d%d%d", &u, &v, &w);
dist[u][v] = w;
n = MAX(u, MAX(v, n));
}
fclose(fin);
dijkstra(1);
printD();
printf("\n");
for (i = 1; i <= n; ++i) {
printf("Path to %d:\n", i);
printPath(i, 0);
printf("\n");
}
return 0;
}
As you can see, there are two paths from node 1 to node 3: 1 -> 2 -> 3 and 1 -> 4 -> 2 -> 3 both of length 6.
Now, what does the programme output?
Distances:
1 2 3 4 5
0 5 6 3 5
Path to 1:
-1
Path to 2:
-2
|-1
|-4
| |-1
Path to 3:
-3
|-2
| |-1
| |-4
| | |-1
Path to 4:
-4
|-1
Path to 5:
-5
|-4
| |-1
It first outputs the distances, and… yes! They’re correct.
Next, it prints those ASCII art drawings. They not drawings. They’re trees with the destination as root and the leafs as the source. To read a path from such a tree, start at a leaf (always 1) and go left, reading the first numbers you can see above.
Let’s find the paths to node 3. There are two leafs, so there are two paths of minimal length. The first one is 1 -> 4 -> 2 -> 3. The second one is 1 -> 2 -> 3. Check on the graph.
That’s it. If you’re up to a challenge, implement prev as an array of linked lists.
In this article, I describe a simple (adds less than 1min of work) way to speed up Dijkstra’s Algorithm for finding the single source shortest path to every node in a graph.
In a previous post I described the simple O(n2) implementation of the algorithm. Here, I focus on a method that will probably speed up the algorithm.
Why Bother
The previous implementation of the algorithm ran in O(n2) time, where n is the number of nodes in the graph. This means that for a graph of, say 100 nodes, it would do about 100 * 100 = 100000 calculations. Considering that computers nowadays are said to be able to do about 100000000 (a hundred million) calculations per second, we’re fine, and the programme will finish in well under a second. But what if we have a graph with 100000 nodes? This might take 100 seconds to run. Now we’re in trouble. We need a faster algorithm.
The two most common ways to speed up Dijkstra’s Algorithm are to implement the finding of the closest node not yet visited as priority queues. Usually heaps or Fibonacci Heaps are used for this purpose (Fibonacci Heaps were actually invented for this).
Heaps are somewhat difficult to implement and Fibonacci Heaps are horror to implement. Incidentally, there’s a very easy of speeding it up.
Just Use Queues
The idea is to simply use queues instead of priority queues. This way provides nowhere near the same level of speedup (the algorithm is still O(n2)), but it makes it run faster, on average, by a factor of 4.
Some bad news: a carefully crafted graph could slow this algorithm down to O(n3). As a rule, graphs in real life are never like this, and, as the method isn’t widely known, test sets for contests are not written to catch this optimisation.
Now for the good news: it’s shockingly easy to write. Compare the old dijkstra1() with the new dijkstra2().
void dijkstra1(int s) {
int i, k, mini;
int visited[GRAPHSIZE];
for (i = 1; i <= n; ++i) {
d1[i] = INFINITY;
visited[i] = 0; /* the i-th element has not yet been visited */
}
d1[s] = 0;
for (k = 1; k <= n; ++k) {
mini = -1;
for (i = 1; i <= n; ++i)
if (!visited[i] && ((mini == -1) || (d1[i] < d1[mini])))
mini = i;
visited[mini] = 1;
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d1[mini] + dist[mini][i] < d1[i])
d1[i] = d1[mini] + dist[mini][i];
}
}
void dijkstra2(int s) {
int queue[GRAPHSIZE];
char inQueue[GRAPHSIZE];
int begq = 0,
endq = 0;
int i, mini;
int visited[GRAPHSIZE];
for (i = 1; i <= n; ++i) {
d2[i] = INFINITY;
visited[i] = 0; /* the i-th element has not yet been visited */
inQueue[i] = 0;
}
d2[s] = 0;
queue[endq] = s;
endq = (endq + 1) % GRAPHSIZE;
while (begq != endq) {
mini = queue[begq];
begq = (begq + 1) % GRAPHSIZE;
inQueue[mini] = 0;
visited[mini] = 1;
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d2[mini] + dist[mini][i] < d2[i]) {
d2[i] = d2[mini] + dist[mini][i];
if (!inQueue[i]) {
queue[endq] = i;
endq = (endq + 1) % GRAPHSIZE;
inQueue[i] = 1;
}
}
}
}
What’s changed? First, we define several new variables. These, together, make up the queue:
int queue[GRAPHSIZE];
char inQueue[GRAPHSIZE];
int begq = 0,
endq = 0;
Next, during the initialisation part of the function, we mark all nodes as not being in the queue.
for (i = 1; i <= n; ++i) {
/* OTHER INITIALISATIONS (look at the programme) */
inQueue[i] = 0;
}
Now, add the source node to the queue.
queue[endq] = s;
endq = (endq + 1) % GRAPHSIZE;
What does this do? The first line add s to the end of the queue. The second line moves the end of the queue one step to the right (I’ll explain a few paragraphs down). The modulo operation here is not really necessary, but I like to be consistent.
At this point we’ll start looping. When do we stop? The idea here is that a node is in the queue when its neighbours need to be updated (i.e. when a new shortest path might be found leading to them). So, we stop when the queue is empty. Note that this occurs when begq == endq and not when !(begq < endq). So, while (begq < endq) is incorrect because, in one case, begq will be greater then endq.
What was the first thing we did in the loop? We were supposed to find the closest node not yet visited. Now, we merely take the first node from the queue.
Here, the first element is pop’d out of the queue, the head of the queue is moved one step to the right and the element is marked as not being in the queue. The problem with queues in general, and this one in particular is that the part of them that actually hold the elements tends to move around. Here, every insert moves the tail one step to the right and every pop moves the head one step to the right. Consider the following sequence of operations:
Moves 1 through 8 clearly show that, while the size of the information content of the queue changes erratically, it constantly moves to the right. What happened at 9? The queue got to the end of available memory and wrapped around to the beginning. This is the purpose of (begq + 1) % GRAPHSIZE and (endq + 1) % GRAPHSIZE. It turns 7, 8, 9, etc. into 1, 2, 3, etc. But won’t endq overrun begq? No, the use of inQueue guarantees that no element will be inserted in the queue more than once. And as the queue is of size GRAPHSIZE, no overrun is possible.
So far, so good. One last modification: when we update the distance to a node, we add it to the queue (if it’s not already in it).
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d2[mini] + dist[mini][i] < d2[i]) {
d2[i] = d2[mini] + dist[mini][i];
if (!inQueue[i]) {
queue[endq] = i;
endq = (endq + 1) % GRAPHSIZE;
inQueue[i] = 1;
}
}
Comparing the speed
When I first wrote this, I wanted to be able to check that it outputs correct results and I wanted to see how much faster it is. The following programme does both. The function cmpd() checks the output against that given by the simple implementation and the various clock() calls littered through the code time the two functions.
Here’s the code in C (dijkstra2.c): Note: Source might be mangled by WordPress, consider downloading the file.
#include <stdio.h>
#include <time.h>
#define GRAPHSIZE 2048
#define INFINITY GRAPHSIZE*GRAPHSIZE
#define MAX(a, b) ((a > b) ? (a) : (b))
int e; /* The number of nonzero edges in the graph */
int n; /* The number of nodes in the graph */
long dist[GRAPHSIZE][GRAPHSIZE]; /* dist[i][j] is the distance between node i and j; or 0 if there is no direct connection */
long d1[GRAPHSIZE], d2[GRAPHSIZE]; /* d[i] is the length of the shortest path between the source (s) and node i */
void dijkstra1(int s) {
int i, k, mini;
int visited[GRAPHSIZE];
for (i = 1; i <= n; ++i) {
d1[i] = INFINITY;
visited[i] = 0; /* the i-th element has not yet been visited */
}
d1[s] = 0;
for (k = 1; k <= n; ++k) {
mini = -1;
for (i = 1; i <= n; ++i)
if (!visited[i] && ((mini == -1) || (d1[i] < d1[mini])))
mini = i;
visited[mini] = 1;
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d1[mini] + dist[mini][i] < d1[i])
d1[i] = d1[mini] + dist[mini][i];
}
}
void dijkstra2(int s) {
int queue[GRAPHSIZE];
char inQueue[GRAPHSIZE];
int begq = 0,
endq = 0;
int i, mini;
int visited[GRAPHSIZE];
for (i = 1; i <= n; ++i) {
d2[i] = INFINITY;
visited[i] = 0; /* the i-th element has not yet been visited */
inQueue[i] = 0;
}
d2[s] = 0;
queue[endq] = s;
endq = (endq + 1) % GRAPHSIZE;
while (begq != endq) {
mini = queue[begq];
begq = (begq + 1) % GRAPHSIZE;
inQueue[mini] = 0;
visited[mini] = 1;
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d2[mini] + dist[mini][i] < d2[i]) {
d2[i] = d2[mini] + dist[mini][i];
if (!inQueue[i]) {
queue[endq] = i;
endq = (endq + 1) % GRAPHSIZE;
inQueue[i] = 1;
}
}
}
}
int cmpd() {
int i;
for (i = 0; i < n; ++i)
if (d1[i] != d2[i])
return 0;
return 1;
}
int main(int argc, char *argv[]) {
int i, j;
int u, v, w;
long t1 = 0,
t2 = 0;
FILE *fin = fopen("dist2.txt", "r");
fscanf(fin, "%d", &e);
for (i = 0; i < e; ++i)
for (j = 0; j < e; ++j)
dist[i][j] = 0;
n = -1;
for (i = 0; i < e; ++i) {
fscanf(fin, "%d%d%d", &u, &v, &w);
dist[u][v] = w;
n = MAX(u, MAX(v, n));
}
fclose(fin);
for (i = 1; i <= n; ++i) {
long aux = clock();
dijkstra1(i);
t1 += clock() - aux;
aux = clock();
dijkstra2(i);
t2 += clock() - aux;
if (i % 10 == 0) {
printf("%d / %d\n", i, n);
fflush(stdout);
}
if (!cmpd()) {
printf("\nResults for %d do NOT match\n", i);
break;
}
}
printf("\n");
printf("Dijkstra O(N^2):\t\t%ld\n", t1);
printf("Dijkstra unstable:\t\t%ld\n", t2);
printf("Ratio:\t\t\t\t%.2f\n", (float)t1/t2);
/* printD(); */
return 0;
}