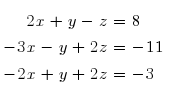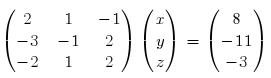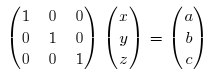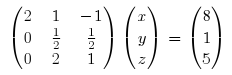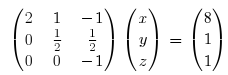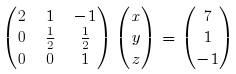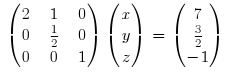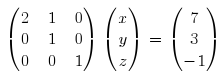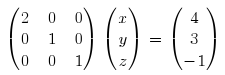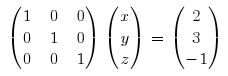In this article, I describe Gauss’ algorithm for solving n linear equations with n unknowns. I also give a sample implementation in C.
The Problem
Let’s say you want to solve the following system of 3 equations with 3 unknowns:
Humans learn that there a two ways to solve this system. Reduction and substitution. Unfortunately, neither of these methods is suitable for a computer.
A simple algorithm (and the one used everywhere even today), was discovered by Gauss more than two hundred years ago. Since then, some refinements have been found, but the basic procedure remains unchanged.
Gaussian Elimination
Start by writing the system in matrix form:
If you recall how matrix multiplication works, you’ll see that’s true. If not, it’s enough to notice how the matrix is written: the coefficients of x, y and z are written, side by side, as the rows of a 3×3 matrix; x, y and z are then written as rows of a 3×1 matrix; finally, what’s left of the equality sign is written one under the other as a 3×1 matrix.
So far, this doesn’t actually help, but it does make the following process easier to write. The goal is, through simple transformations, to reach the system, where a, b and c are known.
How do you transform the initial system into the above one? Here’s Gauss’ idea.
Start with the initial system, then perform some operations to get 0s on the first column, on every row but the first.
The operations mentioned are multiplying the first rows by -3/2 and substracting it from the second. Then multiplying the first rows by -1 and substracting it from the third. What is -3/2? It’s first element of the second row divided by the first element of the first row. And -1? It’s the first element of the third row divided by the first element of the first row. NOTE The changes to row 1 are never actually written back into the matrix.
For now we’re done with row 1, so we move on to row 2. The goal here is to get every row on the second column under row 2 to 0. We do this by multiplying the second rows by 4 (i.e. 2 / (1 / 2)) and substracting it from the third rows.
Now it’s easy to find the value of z. Just multiply the third column by -1 (i.e. -1/1).
ERRATA: The 7 in the above matrix should be an 8.
Knowing the value of z, we can now eliminate it from the other two equations.
Now, we can find the value of y and eliminate y from the first equation.
And, finally, the value of x is:
And with that, we’re done.
The Programme
Unfortunately, this is easier said than done. The actual computer programme has to take into account divisions by zero and numerical instabilities. This adds to the complexity of forwardSubstitution().
#include <stdio.h>
int n;
float a[10][11];
void forwardSubstitution() {
int i, j, k, max;
float t;
for (i = 0; i < n; ++i) {
max = i;
for (j = i + 1; j < n; ++j)
if (a[j][i] > a[max][i])
max = j;
for (j = 0; j < n + 1; ++j) {
t = a[max][j];
a[max][j] = a[i][j];
a[i][j] = t;
}
for (j = n; j >= i; --j)
for (k = i + 1; k < n; ++k)
a[k][j] -= a[k][i]/a[i][i] * a[i][j];
/* for (k = 0; k < n; ++k) {
for (j = 0; j < n + 1; ++j)
printf("%.2f\t", a[k][j]);
printf("\n");
}*/
}
}
void reverseElimination() {
int i, j;
for (i = n - 1; i >= 0; --i) {
a[i][n] = a[i][n] / a[i][i];
a[i][i] = 1;
for (j = i - 1; j >= 0; --j) {
a[j][n] -= a[j][i] * a[i][n];
a[j][i] = 0;
}
}
}
void gauss() {
int i, j;
forwardSubstitution();
reverseElimination();
for (i = 0; i < n; ++i) {
for (j = 0; j < n + 1; ++j)
printf("%.2f\t", a[i][j]);
printf("\n");
}
}
int main(int argc, char *argv[]) {
int i, j;
FILE *fin = fopen("gauss.in", "r");
fscanf(fin, "%d", &n);
for (i = 0; i < n; ++i)
for (j = 0; j < n + 1; ++j)
fscanf(fin, "%f", &a[i][j]);
fclose(fin);
gauss();
return 0;
}
In the above code, the first two for-s of forwardSubstitution(), just swap two rows so as to diminish the possibilities of some bad rounding errors. Also, if it exists with a division by zero error, that probably means the system cannot be solved.
And here’s the input file for the example (gauss.in) (save it as gauss.in): 3
2 1 -1 8
-3 -1 2 -11
-2 1 2 -3
In this article I describe Dijkstra’s algorithm for finding the shortest path from one source to all the other vertexes in a graph. Afterwards, I provide the source code in C of a simple implementation.
To understand this you should know what a graph is, and how to store one in memory. If in doubt check this and this.
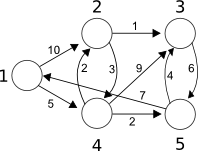
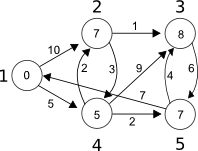
Given the following graph calculate the length of the shortest path from node 1 to every other node.
Lets take the nodes 1 and 3. There are several paths (1 -> 4 -> 3, 1 -> 2 -> 3, etc.), but the shortest of them is 1 -> 4 -> 2 -> 3 of length 9. Our job is to find it.
The Algorithm
Dijkstra’s algorithm is one of the most common solutions to this problem. Even so, it only works on graphs which have no edges of negative weight, and the actual speed of the algorithm can vary from O(n*lg(lg(n))) to O(n2).
The idea is somewhat simple:
Take the length of the shortest path to all nodes to be infinity. Mark the length of the shortest path to the source as 0.
Now, we already know that the graph has no edges of negative weight so the a path of length 0 is the best we can come up with. The path to the source is 0, so it’s optimal.
This algorithm works by making the paths to one more node optimal at each step. So, at the kth step, you know for sure that there are at least k nodes to which you know the shortest path.
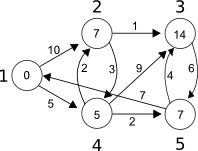
At each step, choose the node, which is not yet optimal, but which is closest to the source; i.e. the node to which the current calculated shortest path is smallest. Then, from it, try to optimise the path to every node connected to it. Finally, mark the said node as optimal (visited, if you prefer). In the previous example, the node which is closest to the source and is not yet optimal is the source. From it, you can optimise the path to nodes 2 and 4.
At this point, the only visited/optimal node is 0. Now we have to redo this step 4 more times (to ensure that all nodes are optimal).
The next node to consider is 4:
It’s worthwhile to note that at this step, we’ve also found a better path to node 2. Next is node 2:
Finally, we look at nodes 5 and 3 (none of which offer any optimisations):
The actual code in C looks something like this:
void dijkstra(int s) {
int i, k, mini;
int visited[GRAPHSIZE];
for (i = 1; i <= n; ++i) {
d[i] = INFINITY;
visited[i] = 0; /* the i-th element has not yet been visited */
}
d[s] = 0;
for (k = 1; k <= n; ++k) {
mini = -1;
for (i = 1; i <= n; ++i)
if (!visited[i] && ((mini == -1) || (d[i] < d[mini])))
mini = i;
visited[mini] = 1;
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d[mini] + dist[mini][i] < d[i])
d[i] = d[mini] + dist[mini][i];
}
}
The Programme
Putting the above into context, we get the O(n2) implementation. This works well for most graphs (it will not work for graphs with negative weight edges), and it’s quite fast.
#include <stdio.h>
#define GRAPHSIZE 2048
#define INFINITY GRAPHSIZE*GRAPHSIZE
#define MAX(a, b) ((a > b) ? (a) : (b))
int e; /* The number of nonzero edges in the graph */
int n; /* The number of nodes in the graph */
long dist[GRAPHSIZE][GRAPHSIZE]; /* dist[i][j] is the distance between node i and j; or 0 if there is no direct connection */
long d[GRAPHSIZE]; /* d[i] is the length of the shortest path between the source (s) and node i */
void printD() {
int i;
for (i = 1; i <= n; ++i)
printf("%10d", i);
printf("\n");
for (i = 1; i <= n; ++i) {
printf("%10ld", d[i]);
}
printf("\n");
}
void dijkstra(int s) {
int i, k, mini;
int visited[GRAPHSIZE];
for (i = 1; i <= n; ++i) {
d[i] = INFINITY;
visited[i] = 0; /* the i-th element has not yet been visited */
}
d[s] = 0;
for (k = 1; k <= n; ++k) {
mini = -1;
for (i = 1; i <= n; ++i)
if (!visited[i] && ((mini == -1) || (d[i] < d[mini])))
mini = i;
visited[mini] = 1;
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d[mini] + dist[mini][i] < d[i])
d[i] = d[mini] + dist[mini][i];
}
}
int main(int argc, char *argv[]) {
int i, j;
int u, v, w;
FILE *fin = fopen("dist.txt", "r");
fscanf(fin, "%d", &e);
for (i = 0; i < e; ++i)
for (j = 0; j < e; ++j)
dist[i][j] = 0;
n = -1;
for (i = 0; i < e; ++i) {
fscanf(fin, "%d%d%d", &u, &v, &w);
dist[u][v] = w;
n = MAX(u, MAX(v, n));
}
fclose(fin);
dijkstra(1);
printD();
return 0;
}
the following e lines contain 3 numbers: u, v and w signifying that there’s an edge from u to v of weight w
That’s it. Good luck and have fun. Always open to comments.
Finding the shortest path
UPDATE In response to campOs‘ comment.
Now we know the distance between the source node and any other node (the distance to the ith node is remembered in d[i]). But suppose we also need the path (which nodes make up the path).
Look at the above code. Where is d modified? Where is the recorded distance between the source and a node modified? In two places:
Firstly, d[s] is initialised to be 0.
d[s] = 0;
And then, when a new shortest path is found, d[i] is updated accordingly:
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d[mini] + dist[mini][i] < d[i])
d[i] = d[mini] + dist[mini][i];
The important thing to notice here is that when you update the shortest distance to node i, you know the previous node in the path to i. This is, of course, mini. This suggests the solution to our problem.
For every node i other than the source, remember not only the distance to it, but also the previous node in the path to it. Thus we have a new array, prev.
Now, we need to make to modifications. First, we initialise the value of prev[i] to something impossible (say -1) at the start of dijkstra().
for (i = 1; i <= n; ++i) {
d[i] = INFINITY;
prev[i] = -1; /* no path has yet been found to i */
visited[i] = 0; /* the i-th element has not yet been visited */
}
Secondly, we update the value of prev[i] every time a new shortest path is found to i.
for (i = 1; i <= n; ++i)
if (dist[mini][i])
if (d[mini] + dist[mini][i] < d[i]) {
d[i] = d[mini] + dist[mini][i];
prev[i] = mini;
}
Good. For every node reachable from the source we know which node is just before it in the shortest path. For the above example, we would have the following array:
i - prev[i]
1 - -1
2 - 4
3 - 2
4 - 1
5 - 4
Using this, how do you get the path? Let’s say you want to get to 3. Which node comes right before 3? Node 2. Which node comes right before node 2? Node 4. Which node comes before 4? Node 1. We’ve reached the source, so we’re done. Go through this list backwards and you get the path: 1 -> 4 -> 2 -> 3. This is easily implemented with recursion.